不同语言主流的内存回收策略
为什么需要内存回收
主要原因是避免内存泄漏,导致内存占用不断增加。如果不进行内存回收,程序在运行过程中使用的内存会越来越多,最终导致系统的内存资源耗尽。
内存回收策略有哪些?
主动释放
代表语言为 C/C++
需要用户进行手动的内存释放,主要语言为 C
- 优势:手动释放提供更精确的控制,更高的性能
- 劣势:容易造成内存安全等问题。
下面是一个 C 的简单的例子
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int value;
} MyStruct;
int main() {
// 动态分配结构体内存
MyStruct* ptr = (MyStruct*)malloc(sizeof(MyStruct));
// 存储值
ptr->value = 42;
printf("存储的值为: %d\n", ptr->value);
// 手动释放内存
free(ptr);
return 0;
}自动释放
Java
Java 虚拟机提供了完善的 GC 系统使用户不用过多关注在内存回收问题上。
- 优势:代码更简单,无需考虑内存回收。
- 劣势:1、运行期性能损耗 2、通常内存占用更大
标记阶段
Java 虚拟机使用
可达性算法来判断哪些对象需要回收
可达性算法的基本思想是通过一组称为GC Roots的根对象作为起点,然后通过遍历对象图的方式,找到所有与根对象直接或间接相连的对象。所有与根对象相连的对象都被认为是可达的,而未被找到的对象则被认为是不可达的,可以被垃圾回收器回收。
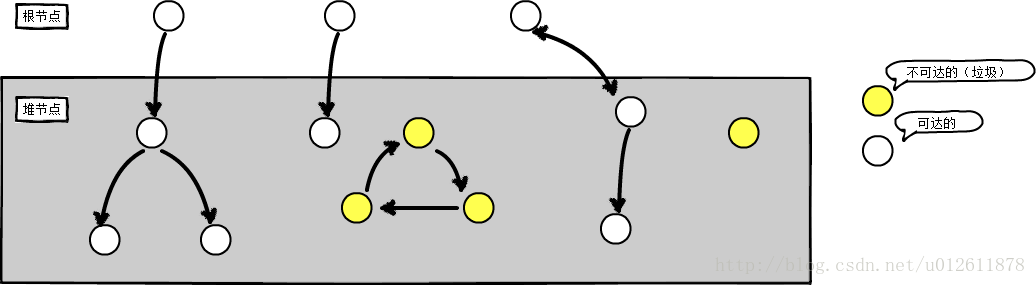
哪些对象作为 GC Roots 对象?
其实 GC Roots 对象就是虚拟机认为一定会活过这次垃圾回收的对象。
- 当前正在执行的方法中的局部变量和输入参数。
- 活动线程的栈帧(包括调用栈)。
- 静态变量(static fields)。
- JNI(Java Native Interface)引用。
清除阶段
直接清除垃圾对象带来的问题:内存碎片化
如果分配超大的需要连续空间对象,这可能会导致提前进行一次垃圾回收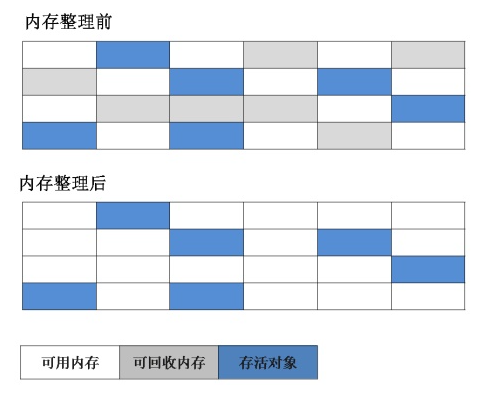
复制
将内存区域分为相等的两块,每次只使用其中的一块,实现简单,运行高效,但是会较为浪费内存空间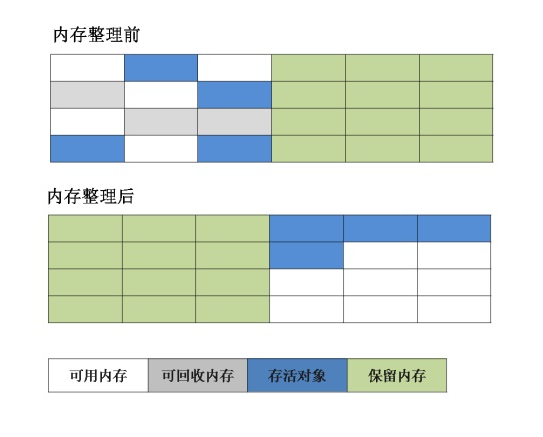
标记-整理算法
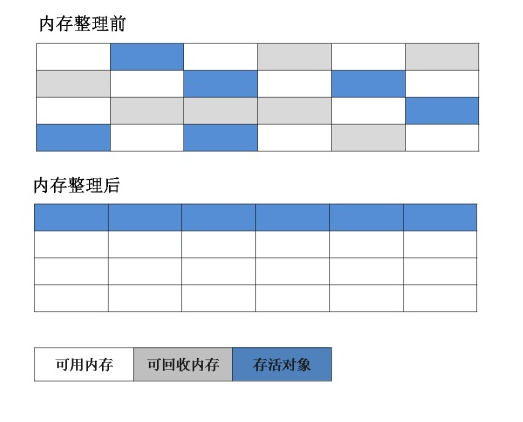
根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
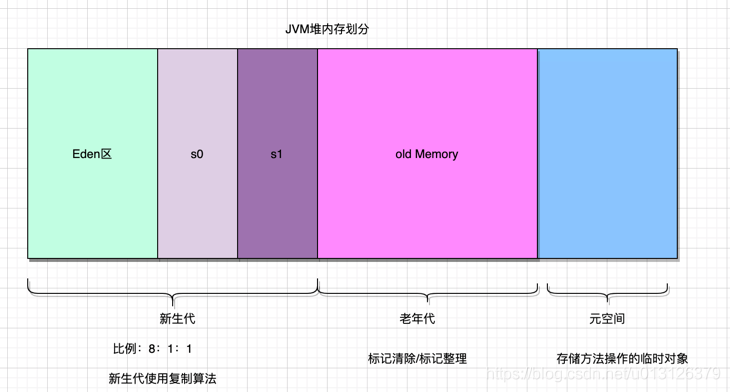
分代收集
由于不同对象的生存周期不同,有的对象存活时间很短,而有些对象存活时间很长,所以 Java 虚拟机将堆内存分为两个区域(忽略 方法区/元空间)
年轻代:内存回收的主要区域,讲究更快的回收速度,更频繁的进行垃圾回收。
老年代:主要存放存活时间较长的对象,尽量避免该区域的垃圾回收。
最终的模型
C++中的 RAII
C++中其中最常用的是使用RAII(Resource Acquisition Is Initialization)原则来自动内存管理。
RAII 原则是什么?
RAII 的基本思想是将资源的生命周期与对象的生命周期绑定在一起。当对象被创建时,它负责获取所需的资源,并在对象被销毁时自动释放资源。这种自动化的资源管理可以避免手动管理资源的麻烦,并提供了更高的代码可靠性和安全性。
对于 C++来说,RAII 会在创建对象(构造函数)时申请资源,对象销毁时(调用析构函数)释放资源。如下列代码所示
#include <iostream>
class Person {
private:
// 人的名字
std::string* name;
};
public:
// 构造函数
Person(const std::string& name) : name(new std::string(name)) {
std::cout << "Person created: " << *this->name << std::endl;
}
// 析构函数,销毁对象时调用
~Person() {
std::cout << "Person destroyed: " << *name << std::endl;
// 释放name
delete name;
}
int main() {
{
Person person("John");
// 在这个作用域结束时,person对象会自动销毁(调用析构函数),内存也会自动释放
}
return 0;
}以上较为基础的简单场景,可以依赖于栈上分配来完成资源的自动回收,如果是main()更改为下面代码会发生什么?
int main() {
{
std::string* name = new std::string("John");
Person person1(name);
Person person2(name);
// 在这个作用域结束时,person1和person2对象会自动销毁,但会导致双重释放同一块内存
}
return 0;
}由于上述代码中的persion1和persion2销毁时会分别调用析构函数,但是name只有一个,这会导致name内存被释放两次,也就是在 C++中的双重释放错误。
如何解决该问题?
- 要么将 name 对象传递给构造函数时复制一份,这样就是不同的 name
- 使用智能指针共享 name 属性,智能指针会在合适的时机自动调用析构函数
C++提供了多种智能指针的实现,其中最常用的是std::shared_ptr和std::unique_ptr
std::shared_ptr是一种共享所有权的智能指针。它使用引用计数来跟踪有多少个shared_ptr共享同一个对象。每当创建一个shared_ptr指向某个对象时,引用计数会增加。当引用计数变为零时,表示没有任何shared_ptr指向该对象,对象的析构函数会被调用,从而释放内存。std::unique_ptr是一种独占所有权的智能指针。它确保在任何时候只有一个unique_ptr指向某个对象。当unique_ptr被销毁时(例如,超出作用域或显式地将其重置为nullptr),对象的析构函数会被调用,从而释放内存。
下面使用了智能指针
std::shared_ptr声明name属性,这样可以方式双重释放。
#include <iostream>
#include <memory>
class Person {
public:
Person(const std::string& name) : name(std::make_unique<std::string>(name)) {
std::cout << "Person created: " << *this->name << std::endl;
}
// 注意这里的析构函数,不再手动释放name的内存,交由智能指针管理
~Person() {
std::cout << "Person destroyed: " << *name << std::endl;
}
private:
std::unique_ptr<std::string> name;
};
int main() {
std::string* name = new std::string("John");
// 计数器+1(此时为1)
Person person1(name);
{
// 计数器+1(此时为2)
Person person2(name);
}
// 计数器-1(此时为1)
return 0;
}
// 计数器 -1(此时为0),释放`name`内存以上程序使用了shared_ptr管理name,当persion2超出作用域时,会销毁persion2对象,但是不会释放name,因为析构函数中没有释放name,但是会导致name计数器-1,由于智能指针的存在此时不会释放name内存,直到persion1对象也被释放才计数器归 0 时才会真正的释放name
引用计数无法处理的的问题?
循环应用是什么
如下图所示,A 依赖 B,B 也依赖 A 的情况称为循环引用,这种情况下因为计数器一直为 1,因为双方都持有对方的引用,而且无法释放任何一方,这可能会导致内存泄漏。
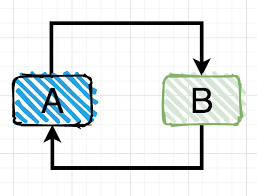
如何处理循环引用?
使用weak_ptr来声明弱引用指针,弱指针不会增加引用计数,这种情况下可以打破本身构成的环结构,破坏环结构之后可以轻松的依赖智能指针回收对象。
Rust
Rust 不需要手动的内存处理,也没有运行期间的垃圾回收导致的性能损耗,Rust 通过"所有权模型",它允许在编译时进行内存管理,以避免运行时的内存错误
总体来说,Rust同样依赖于RAII原则,C++中的析构函数在Rust中表现为Drop 特征,不过Rust在C++的场景下做了更多相关的内存安全检查,避免出现一些内存安全问题。
所有权(Ownership):Rust 中的每个值都有一个所有者,只能有一个所有者。当值被绑定到一个新的变量时,所有权会从旧的变量转移到新的变量。当所有者超出范围时,该值将被销毁。
所有权类似于
C++中的unique_ptr
fn main() {
let s1 = String::from("Hello");
let s2 = s1;
// 在此处尝试使用 s1 将会导致编译错误,因为所有权已经转移给s2
println!("s1: {}", s1);
}所有权不仅能转移给引用,同样能转移给函数
fn main() {
let s = String::from("Hello");
take_ownership(s);
// 在此处尝试使用 s 将会导致编译错误,因为所有权已经转移给 take_ownership函数
println!("s: {}", s);
}
fn take_ownership(s: String) {
println!("Inside take_ownership: {}", s);
// 在函数结束时,s 的所有权将被释放,字符串将被销毁
}- 借用(Borrowing):Rust 允许通过借用来临时地访问所有者的值,而不获取所有权。借用可以是不可变的(
&T)或可变的(&mut T)。借用的生命周期受限于借用者的作用域,这样可以在编译时检查悬挂指针和数据竞争等问题。
fn borrow_string(s: &str) {
println!("Inside borrow_string: {}", s);
// 在函数内部,我们可以使用 s,但是不能修改它
}
fn main() {
let s = String::from("Hello");
borrow_string(&s);
println!("Main: {}", s); // 正常运行,s 的所有权没有转移
}生命周期(Lifetime):Rust 使用生命周期来跟踪借用的有效范围。生命周期注解(
'a)用于指定引用的有效期,并确保引用不会超出其所引用的值的生命周期。这个主要是防止悬垂指针的问题。以下代码会编译报错
因为Rust需要准确的知道longest方法返回的是x还是y以对以对返回值做出检查,检查其是否可能引用了已经释放的变量或者对象。由于在编译期无法得知到底返回的是x还是y,结果导致编译报错。
fn main() {
let str1:&str= "abcd";
let str2:&str= "xyz";
// 返回两个字符串中较长的那一个
let result = longest(str1, str2);
println!("The longest string is {}", result);
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}修改如下
在程序中强制指定x,y,和返回值的生命周期关系,表示三者的生命周期相同,继而能通过借用检查器的检查。
fn main() {
let str1 = "abc";
let str2 = "xyz";
let result = longest(str1, str2);
println!("The longest string is {}", result);
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}总结
目前来垃圾回收主要分成三类
- 强制手动回收内存:
C/C++ - 拥有完备的垃圾回收器,用户无需关注内存回收:
JS/Java/Python/Go - 借助于 RAII,引用计数等等自动完成内存回收:
C++/Rust/Swift